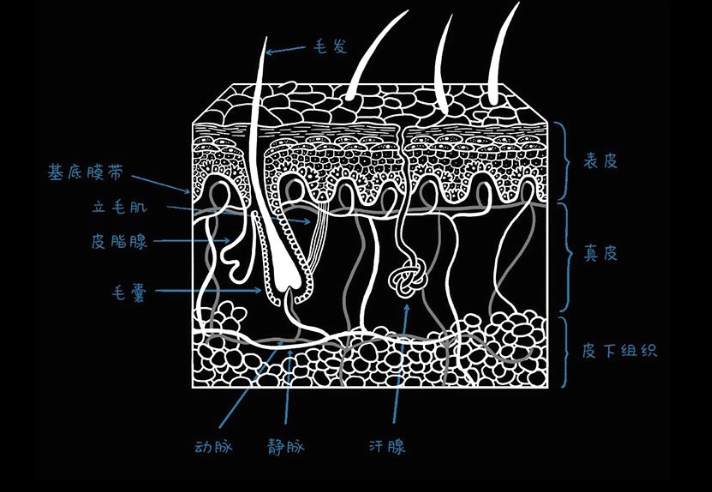
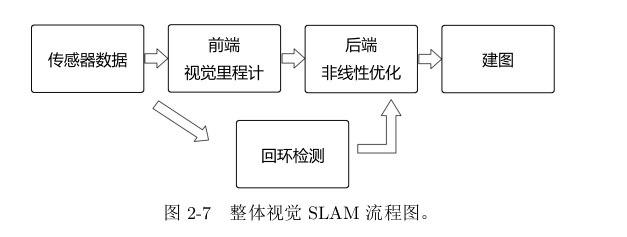
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
| #include <opencv4/opencv2/highgui.hpp>
#include <opencv4/opencv2/opencv.hpp>
#include <opencv4/opencv2/imgproc.hpp>
#include <opencv4/opencv2/features2d.hpp>
#include <opencv4/opencv2/core.hpp>
#include <opencv4/opencv2/calib3d.hpp>
#include <iostream>
using namespace cv;
using namespace std;
int main(int argc, char **argv)
{
cout << CV_VERSION << endl;
Mat img1 = imread("001.JPG");
Mat img2 = imread("002.JPG");
Ptr<SIFT> detector = SIFT::create();
vector<KeyPoint> keypoints1, keypoints2;
Mat descriptors1, descriptors2;
detector->detectAndCompute(img1, noArray(), keypoints1, descriptors1);
detector->detectAndCompute(img2, noArray(), keypoints2, descriptors2);
Ptr<DescriptorMatcher> matcher = DescriptorMatcher::create(DescriptorMatcher::FLANNBASED);
vector<vector<DMatch>> knn_matches;
matcher->knnMatch(descriptors1, descriptors2, knn_matches, 2);
const float ratio_thresh = 0.5f;
vector<DMatch> good_matches;
for(size_t i=0; i<knn_matches.size();i++)
{
if(knn_matches[i][0].distance < ratio_thresh * knn_matches[i][1].distance)
{
good_matches.push_back(knn_matches[i][0]);
}
}
Mat img_matches;
drawMatches(img1, keypoints1, img2, keypoints2, good_matches, img_matches);
std::vector<Point2f> obj;
std::vector<Point2f> scene;
for( size_t i = 0; i < good_matches.size(); i++ )
{
obj.push_back( keypoints1[ good_matches[i].queryIdx ].pt );
scene.push_back( keypoints2[ good_matches[i].trainIdx ].pt );
}
Mat H = findHomography( obj, scene, RANSAC );
cout << H << endl;
std::vector<Point2f> obj_corners(4);
obj_corners[0] = Point2f(0, 0);
obj_corners[1] = Point2f( (float)img1.cols, 0 );
obj_corners[2] = Point2f( (float)img1.cols, (float)img1.rows );
obj_corners[3] = Point2f( 0, (float)img1.rows );
std::vector<Point2f> scene_corners(4);
perspectiveTransform( obj_corners, scene_corners, H);
line( img_matches, scene_corners[0] + Point2f((float)img1.cols, 0),
scene_corners[1] + Point2f((float)img1.cols, 0), Scalar(0, 255, 0), 4 );
line( img_matches, scene_corners[1] + Point2f((float)img1.cols, 0),
scene_corners[2] + Point2f((float)img1.cols, 0), Scalar( 0, 255, 0), 4 );
line( img_matches, scene_corners[2] + Point2f((float)img1.cols, 0),
scene_corners[3] + Point2f((float)img1.cols, 0), Scalar( 0, 255, 0), 4 );
line( img_matches, scene_corners[3] + Point2f((float)img1.cols, 0),
scene_corners[0] + Point2f((float)img1.cols, 0), Scalar( 0, 255, 0), 4 );
namedWindow("Matches", WINDOW_NORMAL);
imshow("Matches", img_matches );
waitKey();
return 0;
}
|